|
|
.NET database and distributed computing tools |
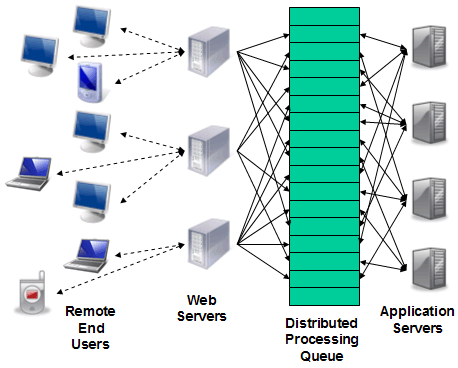
Figure 1. A typical distributed processing scenario
| Figure 1 (above) depicts a typical distributed processing scenario: many interactive users remotely issuing transactions against a shared database. End users communicate across the Internet with a pool of web servers, which add tasks to the queue, so that work can be offloaded for asynchronous processing by other machines. | Application servers pick up prioritized tasks from the queue, perform the appropriate actions, and flag queue entries as completed, deleting records periodically so the queue doesn't grow indefinitely. The BQF queue is simply a table in a database containing a variety of other tables that can be accessed by the web servers and application servers. |
Scalability
| Each of the components of a distributed processing system can be scaled to increase its capacity and improve performance as required. High-speed communications hardware makes it possible to "scale out" simply by adding more web servers, but the need for this expense can be reduced by utilizing distributed processing to keep web servers focused on their primary function. Likewise, we can increase the number of application servers to handle a virtually unlimited workload, and these machines need only be able to communicate with the database. | The queue itself can be scaled simply by
introducing multiple queues, if the degree of contention for a single queue
makes this necessary. (BQF is designed to minimize the duration and scope of
locking that takes place during queuing operations, so a high degree of
performance is possible even with a single queue.) Finally, the database can be scaled up (as well as out) to an extremely high capacity. We'll go into database scalability further, but first let's examine the design of BQF in more detail. |
Queue Structure
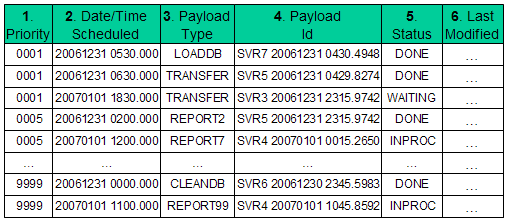
Figure 2. BQF record layout and sample data
Fields in each BQF queue recordA BQF queue is a database table whose records contain the following fields:
|
The BQF table indexThe queue has a single index, which defines a primary key formed from the concatenation of fields 1 - 5, i.e. all except the Last Modified information. Keys are guaranteed unique, because each queue record is associated with a unique payload. This index allows fast lookup of a given queue record, as well as providing an efficient basis for prioritized, first-in, first-out (FIFO) processing. By avoiding the need to maintain multiple indexes, queue manipulations are kept as fast as possible, and the chance of deadlock is reduced. Another aspect of BQF index optimization is the characteristic that the location of keys within the index tends to be relatively stable as entries are added, updated, and deleted. This minimizes the extent of dynamic index reorganization, further reducing contention during updates to index pages under intensive concurrent usage. Now let's look at the basic queuing operations to see how these are designed not only to work efficiently with the index, but also to make use of the most efficient modes of synchronization and transaction processing. |
Basic Queuing Operations
BQF supports the following three primary
functions:
As an optimization, BQF automatically reuses precompiled SQL for repeatedly used commands. Additional BQF functions allow dynamic batching of multiple queue items, to further reduce the overhead of handling a high volume of small transactions. |
|
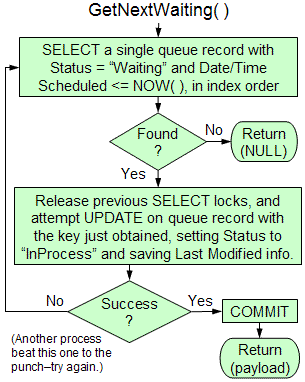
Efficient Garbage Collection
| In order to keep the queue and its accompanying
payload table(s) from growing endlessly, there must be a mechanism for
"garbage collection", i.e. the
physical deletion of records that are no longer needed. BQF's unique
design increases the efficiency of garbage collection by minimizing its
impact on the speed of the primary queuing functions. BQF garbage collection can operate automatically, as well as support various flexible cleanup options. A novel aspect of BQF's approach is its separation of the action that marks the completion of a task from the actual deletion of the corresponding queue record and its associated resources. Instead of doing an immediate deletion upon the MarkAsDone operation, a very fast update is made to the Status field, and the deletion is deferred. This delayed method of dynamic garbage collection provides a substantial boost in efficiency, as we shall explain. |
To synchronize
concurrent queue manipulations, index pages are locked and unlocked
automatically by the underlying database system (DBMS). The BQF queuing
functions have been designed to enable fast DBMS execution with the briefest
possible duration of locking, so that a high rate of concurrent
activity can be supported. However fast the individual queuing operations, another factor that can dramatically affect queue performance is the pattern of locality among the many operations that take place under intensive usage. If too many actions require locking a common index page, those operations may be slowed down considerably, waiting in turn, instead of running in parallel. Conversely, if the actions are more spread out across multiple index pages, the effect of locking diminishes, because conflicts are less frequent. This is the point of delayed garbage collection: it reduces contention for the most active index pages, thereby enhancing concurrency. |
|
|
|
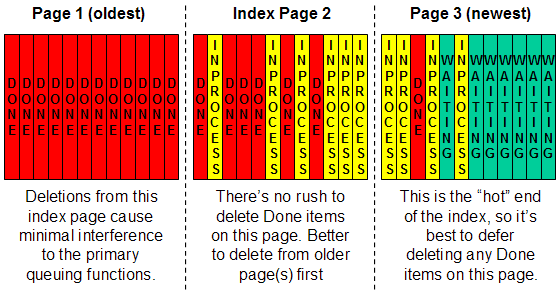
Figure 4. Example of an active queue - Why deletions are
delayed Red items are Done and ready to delete, but it's more efficient to delay garbage collection until the affected pages are not too close to the "hot" end of the queue, at right. |
Guaranteed Recovery from Failures
Leveraging Database Transaction ProcessingOne of the primary motivations for implementing the queue as a database file is to get the benefit of database transaction processing (TP) reliability and recovery features. The queue generally contains valuable information about work to be done, some of which has not yet been recorded elsewhere. The underlying database TP facilities provide assurance, to an arbitrarily high degree of certainty, that the queue itself can be recovered after any crash, up to the most recently committed transaction. Beyond guaranteeing recoverability of the queue, BQF's design further assures that both the queue and the rest of the database can be collectively recovered to a mutually consistent state, one of the fundamental tenets of TP. To accomplish this, BQF simply incorporates the queue directly into the database, rather that treating it as an external entity that must somehow be integrated to work in concert with the DBMS-provided TP mechanism. Besides greatly simplifying a thorny problem, BQF is thus able to employ the most efficient, low-level methods for coordinating fine-grained, asynchronous processing. |
Recovering from Interruptions and Partial FailuresDBMS-level TP only handles a portion of the complete recovery problem, that of restoring the queue and the database to its most recent state. One must also consider how to deal with the system's interrupted condition, so that normal operation can be resumed as soon as possible. Also we must contend with the common situation of partial failures, where one or more application servers crash, but the database and rest of the distributed system keeps running. BQF supports a recovery procedure that enables rapid resumption of normal system operation after such interruptions and partial failures. Only those queue items whose Status is "InProcess" need to be considered, and the recovery of these tasks generally reduces to simply resetting their Status to "Waiting". For partial failures, BQF can use the identifier of a crashed server and time of its demise to narrow down the selection, since the id and timestamp are stored as a part of the "Last Modified" field of each queue record. In short, BQF's recovery procedure is fast, because it can be done in a single efficient pass. |
Summary and Conclusions
| The Base One Queuing Facility demonstrates how it is possible to do high performance, large scale distributed processing, without resorting to complex and costly solutions. Properly used, the native capabilities of modern database management systems can be employed to construct efficient distributed systems that scale to massive proportions. | BQF's design fully exploits the greatest strengths of database technology, indexing and transaction processing, to provide a unique capability that offers speed, reliability, and scalability. Through its simplicity, BQF achieves efficiency, but no less important is the resultant ease it provides to programmers and designers faced with the challenge of building large distributed applications. |
Distributed
Computing | Benefits | Why Grid? |
Architecture | In Depth |
Queuing | Scalability |
BFC
|
|
|||||||
| Home | Products | Consulting | Case Studies | Order | Contents | Contact | About Us |
|
|
|||||||
|
Copyright © 2012, Base One International Corporation |
|||||||